Why Data Modeling is the Key Challenge for Accurate Generative BI
Building an end-to-end B2B Generative BI platform involves handling everything from data ingestion to dashboard and analytics creation. It’s crucial—perhaps now more than ever—to have a robust ETL (Extract, Transform, Load) layer to ensure data is validated and properly managed.
From our experiences with large enterprises, we’ve learned that there’s no one-size-fits-all methodology for handling and processing customer data. Each customer has unique implementations of systems like ERP, PoS, and WMS, along with custom business rules layered on top for reporting and analytics. Therefore, it’s vital to build connections as close to the source systems as possible.
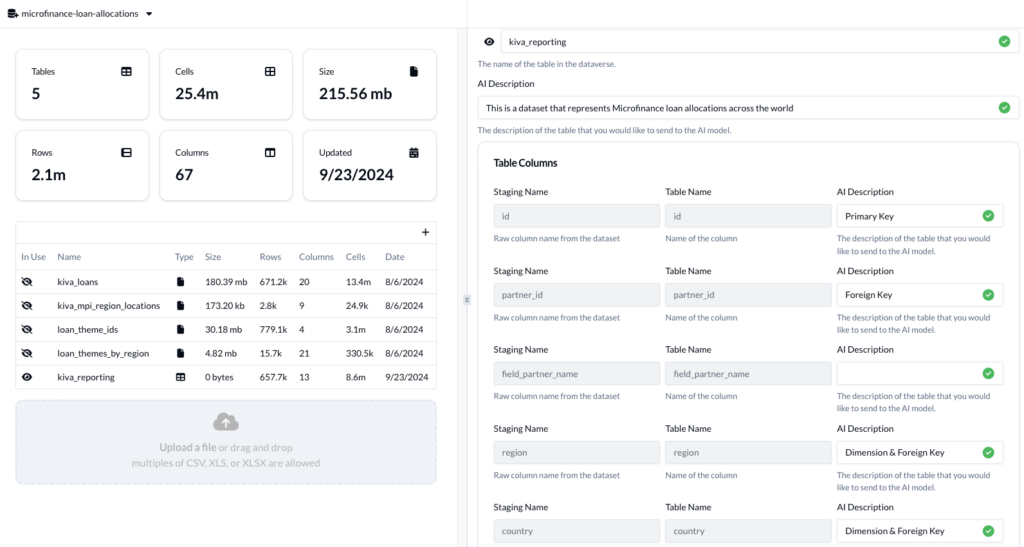
The bottleneck—and the hard problem—of onboarding lies in building the data model for a customer. To do this effectively, you need metadata richness that provides insights into primary and foreign keys, measures and dimensions, low cardinality columns, and more. Constructing this data model with high accuracy is essential for Generative BI to work, enabling companies to make high-fidelity decisions from data with high velocity.
Generative AI models can accelerate this work by generating structure around unstructured information spread across disparate systems or not documented at all. Many companies lack well-documented data models, and feeding generalized schema information into a Generative AI model often results in poor connections between sources. Incorrect column identification and join conditions between tables are common issues.
Connecting closer to the source allows us to access the raw data truth, no matter how messy and unstructured it may be. It’s important that this data isn’t manipulated by human-curated logic and business rules when establishing the foundation of the metadata. Once you’ve established connection points from APIs or SFTPs, you can build validation scripts and upserts to ensure the history of customer data is structured and built accurately. After initial models are built, business rules can be layered on top, and the workflows for enabling this are critical.
For example, building a One Big Table (OBT) view and having that cascade throughout all reporting is significant. This approach allows you to define business rules, measures, and hierarchies only once, ensuring consistency across all necessary points.
Once data is in a cloud data warehouse, you can build a metadata layer that captures table and column attributes, statistics on this data, and tags columns as measures or dimensions. With this foundation, we can begin to automate the data modeling process. AI can help bring things to a starting point.
However, traditional software engineering needs to package this intelligence and build intuitive workflows so users can take action, visualize their data, and make adjustments on the fly. These adjustments need to be reflected in the metadata layer, contributing to its richness so that the models can perform better.
Often, during our customer onboardings, we assist with a one-time historical data load of all transactional data and product, location, and supplier information. This helps build a foundation in the data domain and addresses the cold start of building that initial data model.
From here, it’s important that this metadata layer is automatic and dynamic as more data comes in. For example, at B/eye, we’ve built a proprietary ETL that’s as generalized as possible. We can take any input in the form of CSV, Excel, or Parquet files, load it in, and add it to the data model. As new data arrives, our system determines from the metadata intelligence whether this new file adds more history to something that already exists (and should append) or should be treated as a net new source.